Web Scraping
Overview
Time: 0 minObjectives
Understand the concepts of Web scraping
Hands on session on Web Scrapping
Introduction
One of the important step of a data science project is the Data Collection step. Based on the Business understanding and problem statement, we have to collect the data from multiple sources. It is one of the most important step because the quality and the quantity of the data retrieved from multiple sources will have a significant impact on the final model. In real world, there are many datasets available in opensource websites that are being used by various data scientist, but for many problem statement, these generic datasets cannot be used. Therefore, for few problem statements we have to retrieve the data ourselves from various sources.
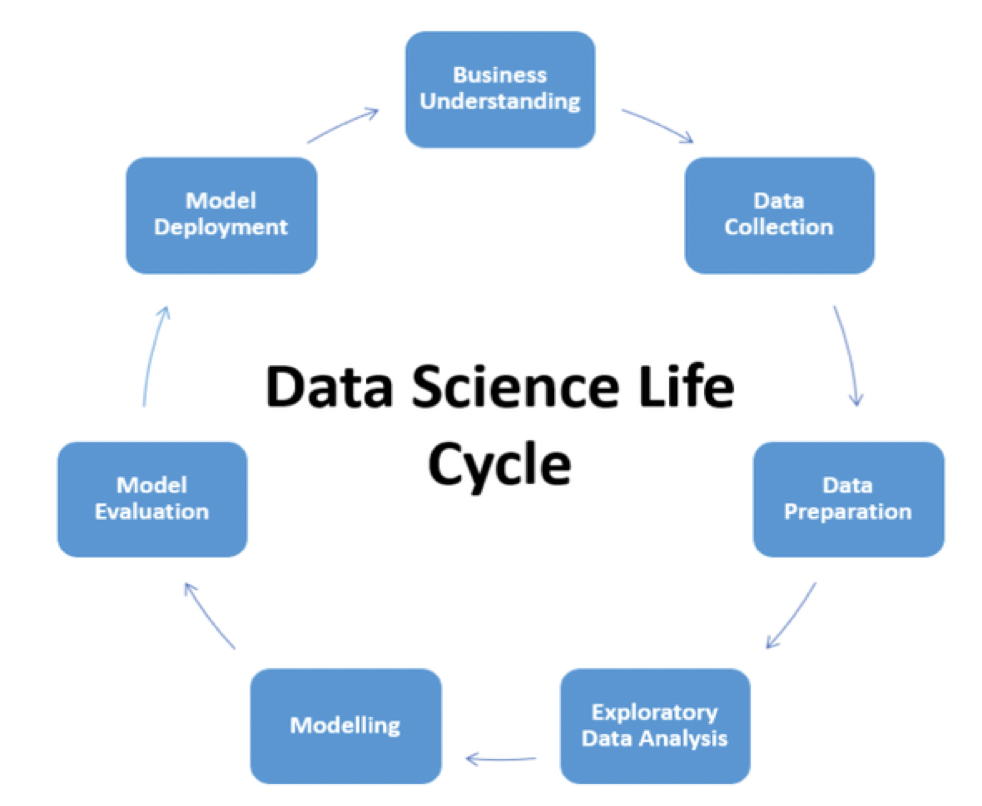
The common sources for data collection are:
- Directly downloading a dataset from open source websites
- Database Query
- Scrap data from a webpage
- Query an API.
Web Scrapping
Web scraping is the process of extracting data from a website. This data is gathered and then exported into a format that is more user-friendly like spreadsheets, JSONs or APIs. Most of the data in the real world is unstructured data in an HTML format which is then converted into structured data in a spreadsheet or a database so that it can be used in various applications. There are many different ways to perform web scraping to obtain data from websites. These include using online services, particular API’s or even creating your code for web scraping from scratch. Many large websites, like Google, Twitter, Facebook, StackOverflow, etc. have API’s that allow you to access their data in a structured format.
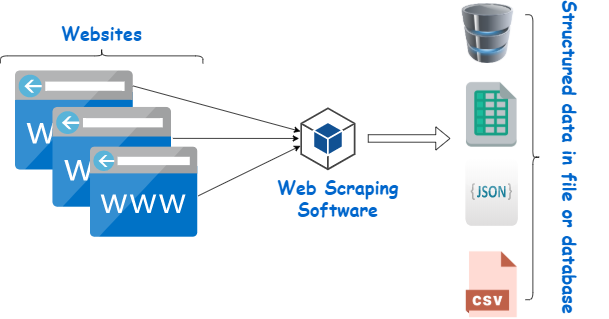
The crawler and the scraper are required for web scraping. The crawler is an artificial intelligence program that searches the internet for specific material by following links throughout the internet. A scraper, on the other hand, is a tool designed to extract information from a website. The scraper’s architecture might vary widely depending on the project’s complexity and scope in order to retrieve data fast and reliably.
Automated crawlers can create problems for websites like:
- Multiple requests per second
- Download large files
- Can overwhelm servers
You can check robots.txt in your target website to learn about their rules for spiders and crawlers https://en.wikipedia.org/robots.txt
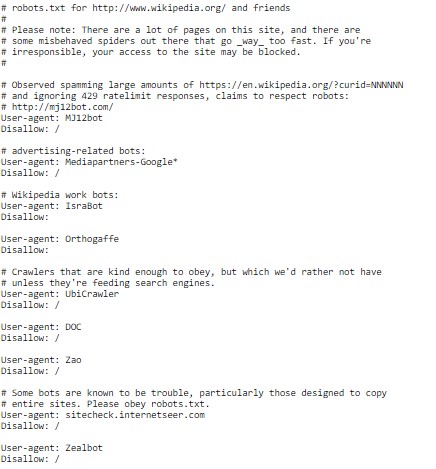
Common challenges you should be aware of when web scraping:
- Check robots.txt for scraper permission. If the owner disallow it, you have to look for an alternative site.
- IP blocking: If a website receives high number of requests from the same IP address, it will block it or restrict its access.
- CAPTCHAs ( Completely Automated Public Turing test to tell Computers and Humans Apart)
- Dynamic web content
Key Points
Discussed the concept of Webscraping, crawlers and scrappers
Hands on session for scrapping data from wikipedia